




maat
Members
-
Benutzer seit
-
Letzter Besuch
-
Hallo Testling, ich würde zunächst einmal sagen, dass es zumindest bei kleineren Installationen von sagen wir mal unter 100 oder 1000 bricks keinen großen Unterschied machen wird, was die Geschwindigkeit angeht. Vielmehr ist es von Interesse mit welcher Architektur du arbeiten willst. Wenn du ohnehin schon überall Threads verbaut hast und damit auch die Callback Architektur übernommen hast, dann ist das original Binding sicherlich der bessere Weg. Wenn du Callbacks vermeiden willst und lieber mit Generatoren arbeiten willst, dann empfehle ich dir die Asyncio Bindings. Das ist vornehmlich eine Frage des Geschmacks. Ich bin damals auf Asyncio gewechselt, weil ich ein dynamisches System haben wollte, so dass ich Config Updates in Echtzeit einspielen kann. Nach etlichen Versuchen das über die Standardbindings zu machen habe ich aufgegeben. Bei Dutzenden von Sensoren wird das mit den Callback einfach nur noch ein Chaos. Du weißt nie wo sich gerade welche Information befindet, weil sich alle möglichen Callbacks untereinander aufrufen. Um das Programm dann übersichtlich zu gestalten bot sich eine Pipeline/Stream Architektur an. Siehe https://reactivex.io/. Durch die Streams ist der gesamte Informationsfluss sofort ersichtlich und klar. Seit dem sauge ich fleißig Daten aus grob 200 Sensoren in eine Datenbank und bereite das Ganze über Grafana auf.
-
Ich habe eine Frage zu Enumerations beim IP Protocol. Es geht um den CALLBACK_ENUMERATE. Hier gibt es das enumeration_type property, welches etweder 0, 1 oder 2 ist, je nach dem warum der Callback geschickt wird. Es geht mir um die Nummer 2 (Device is disconnected). Laut Docu ist das wie folgt definiert: 2: Device is disconnected (only possible for USB connection). In this case only uid and enumeration_type are valid. Das System verhält sich auch entsprechend. Nun aber zu den neuen Bricklets mit MCU. Diese kann man ja auch resetten und wäre es möglich, dass diese vorher einen disconnect absetzen? Das wäre für die API schöner gelöst, da ich dann aufräumen könnte, egal was das Bricklet danach macht und immerhin ist der Master ja noch da, so dass es hier keine Probleme bezüglich USB/Ethernet gibt.
-
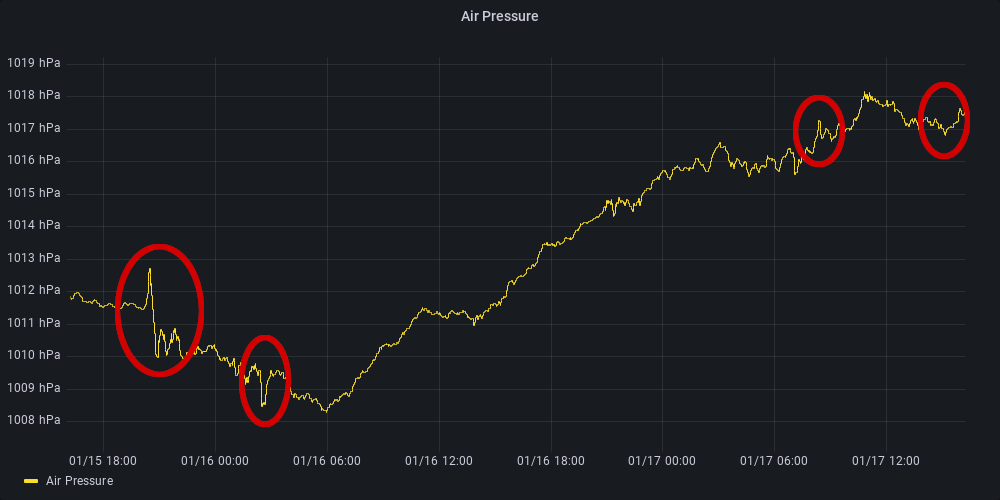
Hallo Tinkerforge Team vielen Dank für tolle Arbeit am Barometer Bricklet! Am Samstag meinte sich ja ein Vulkan in Tonga zu sprengen und es ist der Hammer, wie gut man das beim Barometer Bricklet (v1) sehen konnte. Man konnte sowohl die nach Norden laufende Druckwelle, wie auch die nach Süden laufende sehen und ebenso konnte man sie um Rauschen erkennen, nachdem sie einmal um die Erde gelaufen waren. Top!
-
Die Sache mit den Tinkerforge Bindings und Asyncio wird ja alle Jahre wieder einmal durchgekaut (z.B. hier oder hier). Ich bin nicht besonders glücklich darüber gewesen wie es von @borg vorgeschlagen wurde die TF Bindings in einen Threadpool zu packen. Das macht die ganze Sache sehr, sehr unübersichtlich und man kann kaum erkennen was hier eigentlich noch passiert. Außerdem ist der Code der IP connection über die Jahre ein scheinbar immer mehr organisch gewachsen, so dass hier mehr und mehr Code rein gewandert ist, welcher eigentlich gar nichts mehr mit der IP connection zu tun (no offsense). Da wir die Bricklets aber mit großer Freude im Labor zum Loggen einsetzen, und ich das neue Backend gerne komplett in asyncio haben will, habe ich mich dran gesetzt und einfach eine komplett neue Implementierung der API angefangen. Das Ganze ist auf Github zu finden: https://github.com/PatrickBaus/TinkerforgeAsync Ich habe bisher alle Bricklets implementiert, die ich in die Hände bekommen habe und ein paar Änderungen an der API vorgenommen, die mich entweder gestört haben oder, die nicht zu asyncio gepasst haben. Eine Übersicht der Änderungen ist auf der Github Seite. Die größte Änderung ist sicherlich, dass ich von den base58 codierten uids zu Integern gegangen bin. Hier bin ich aber noch am überlegen, ob ich nicht zumindest auf der Eingabeseite beides akzeptieren sollte. Was die Codestruktur angeht, so habe ich versucht die IP connection extra simpel zu halten und das ganze Dekodieren (außer dem Header) in die bricks/bricklets auszulagern. Dadurch fällt zum einen diese komplett absurde Struktur der High-Level-Callbacks weg und zum anderen bleibt der Code auch schön lokal sichtbar und man wurschtelt nicht in der IP connection irgendwelche Spezialfälle durch. Ich würde mich über Feedback freuen.
-
Ja, genau. Das mit dem Pool bezog sich auf die Zahlen, aus denen ich die Nummern wähle, bzw. ich löse es durch eine Queue, in die die Zahlen zurück gegeben werden, wenn der Request durch ist.
-
Vielen Dank für die schnelle Rückmeldung. Das klingt super! Finde ich spitze, dass ihr die im Protokol drin habt. Damit kann man das ganze schön asynchron hoch ziehen.
-
Guten Tag, ich bin gerade mit Tinkerforge IP Protokoll beschäftigt und da bin ich über die Sequence number gestolpert und habe hierzu eine Frage. In der Doku steht außerdem gibt es zu dem Thema noch den Post von photron hier https://www.tinkerunity.org/topic/2800-sequence-number/?do=findComment&comment=18570. So viel zur Ausgangslage. Nun zu meiner Sache: Wie photron ja schon geschrieben hat, antwortet der Brick immer mir der korrekten Sequence number egal in welcher Reihenfolge ich damit ankomme. So weit so gut, denn dann ist das weniger eine Sequence number, als mehr eine Jobnummer. Angenommen es gäbe irgendwann einen Brick oder eine Firmware, die fähig wäre Jobs asynchron abzuarbeiten (wäre ja jetzt schon denkbar bei der aktuellen Hardware), dann könnte es ja sein, dass der eine oder andere Job etwas länger braucht und dann eben Zahlen belegt sind und ich theoretisch blocken müsste bis der lahmste call irgendwann durch ist, weil ich die Sequence number nicht überspringen darf. Mir geht es nun darum, wie das vermutlich von eurer Seite aus in (ferner) Zukunft gehandhabt wird, denn ich möchte meinen eigenen Code nicht unnötig kompliziert schreiben müssen (blockend). Ein pool aus 14 Zahlen wäre mir hier lieber. Ich kann mir aktuell keinen triftigen Grund überlegen, warum die Reihenfolge eine Rolle spielen sollte. Ich denke auf Paketebene braucht man die Pakete nicht zu sortieren. Auf Datenebene kann man das ja immer noch machen. Aber es gibt vermutlich keinen Grund, warum man Pakete zu einem "Superpaket" zusammensetzen wollte (zumindest aus meiner Sicht). Ich würde mich über eine kleine Rückmeldung freuen.

